Monotonic Neural Network
There are many situations when one would like to recover a monotonic functions from (noisy) data. For example, in a regression setting, that is usually called an isotonic regression model. This can be useful, for example, when modeling a relationship of the type (happiness) ~ F(income) for some unkown function F that one can quite safely assume monotonic increasing.
How do we build a neural architecture such that, for any set of neural weights the neural network represents a function that is increasing along any of the coordinates? That is an old problem, and there are quite a few solutions apparently. For example, I will describe here the basic approach of this 1997 paper (1) by J. Sill.
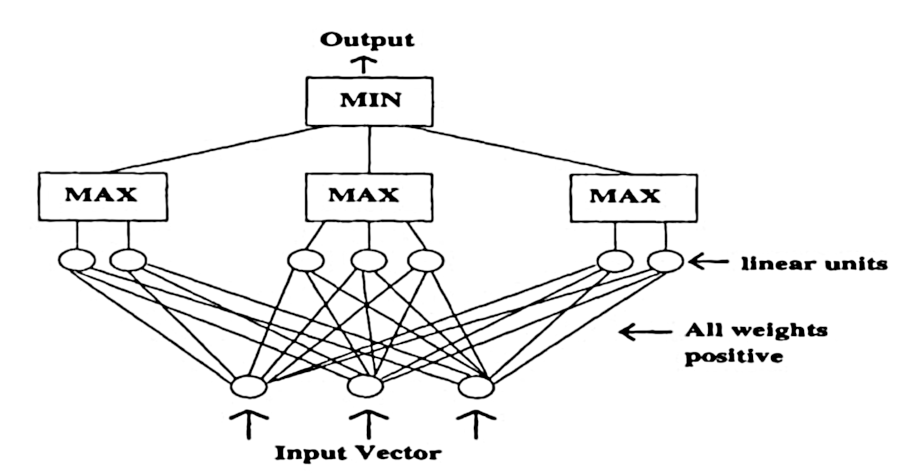
It is based on the fact that if are increasing and continuous functions, then so are their pointwise minimum and pointwise maximum. In other words, the two functions and defined as
and
are also both increasing and continuous functions. To construct an “increasing” neural architecture, one can consequently try to build relatively simple increasing functions and define the output of the neural network as their minimum,
Now, to construct each one of these simple increasing functions , one can choose vectors with non-negative coordinates and biases and define
where is the usual Euclidean dot-product. To inplement this, one can use a soft-plus operation, i.e. with no constraint on , or anything equivalent, to make sure that these weights are nonnegative. Below, I have implemented this with and , initialized all the weights randomly from a centred Gaussian with unit variance, and repeated the experiment times.

Now, we can try to implement a standard regression, but with the constraint that the function is increasing (i.e. isotonic regression). It suffices to minimize the standard Mean Square Error (MSE) with a monotomic neural net. Below shows the dynamics of learning on a simple 1D dataset and with a standard SGD optimizer.
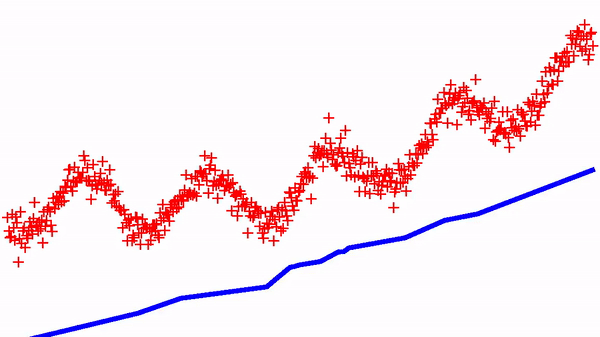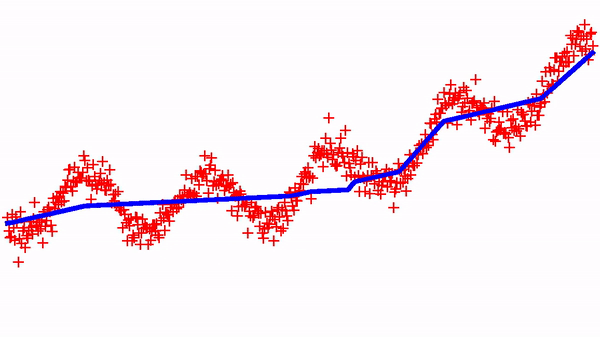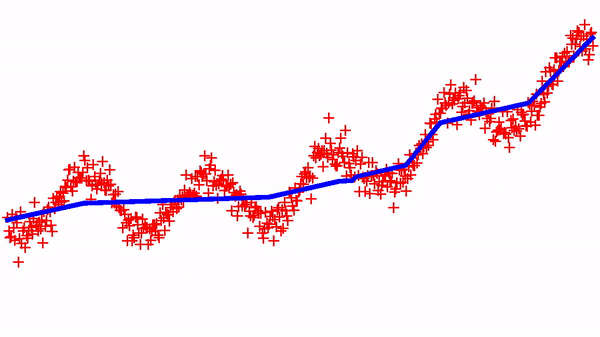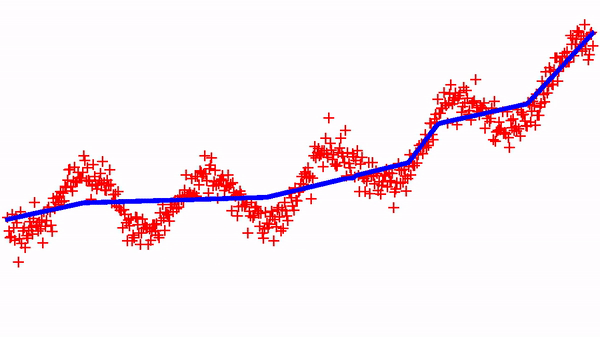
There are variants of this approach for designing neural networks that always represent convex functions — I’ll try to show some simulations in a next blog-post. These monotonic networks are useful in many settings — in a next blog-post, I will use them for implementing a (deep) quantile-regression model…
references
- Sill, J. (1997). Monotonic networks. Advances in neural information processing systems, 10.